

はじめに
前回pytesseractを使いocrを日本語で行う方法について書きました。
ですが、画像の前処理などは行なっておらず精度があまり良くなかったです。
ですので今回はpytesseractでOCRを行う前に前処理を入れてみました。
その時の方法とソースコードを共有するので参考になればと思います。
画像の前処理とは
そもそもなぜ画像の前処理が必要なのかという話です。
前処理は、画像からノイズを除去し、OCRエンジンがテキストをより簡単に解読できるようにするために行われます。
一般的な前処理は次のようなステップで行われます。
- グレースケール化: カラー画像をグレースケールに変換します。これは、他の前処理ステップの基礎となります。
- 二値化: このステップでは、画像を白黒の二値画像に変換します。これは、画像内の文字を明確に区別しやすくするために行われます。通常、閾値処理や適応的閾値処理を使用して行われます。
- ノイズ除去: 画像から不要なノイズを除去します。これは、メディアンフィルタリングやガウシアンブラーなどの手法を使用して行います。
前処理を入れたpytesseractのサンプルソース
上記の画像の前処理を入れたサンプルコードを見てみます。
サンプルソース
サンプルソースは次の通りです。
import cv2
import pytesseract
# 画像を読み込む(グレースケールモードで)
img = cv2.imread('path_to_your_image.png', cv2.IMREAD_GRAYSCALE)
# 二値化
# 150を適切な値に変更します
_, img = cv2.threshold(img, 150, 255, cv2.THRESH_BINARY)
# ノイズ除去
# 5を適切な値に変更します
img = cv2.medianBlur(img, 5)
# OCR適用
text = pytesseract.image_to_string(img, lang='jpn')
print(text)
cv2.imread()関数に第二引数としてcv2.IMREAD_GRAYSCALEを指定することで、画像をグレースケールモードで読み込んでいます。
二値化、ノイズ除去についてはパラメータ調整可能(後述)です。
PyTesseractの精度向上のTips
簡単ですがPyTesseractに関する精度向上のTipsです。
- 適切なPPI(ピクセル密度): 高解像度の画像が最良の結果をもたらすことが一般的です。300PPIは良いスタート地点となります。
- 画像の向き: テキストが通常の水平方向になるように、画像が適切に向けられていることを確認します。
- 適切な言語設定: PyTesseractは多言語対応していますが、適切な言語を指定しないと精度が低下します。例えば日本語のテキストを解析する場合、
lang='jpn'オプションを指定します。
画像認識と結果
参考画像
次の3つの画像をOCRにかけました。これはpyocrと同じものです。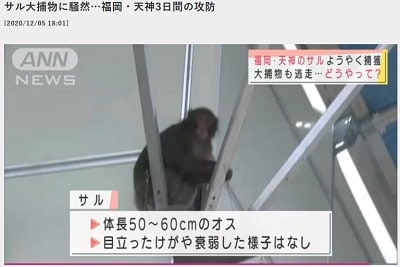
00005.jpeg

00007.jpeg

receipt.jpg
実行結果
実行結果は次の通りです。
00005.jpegの結果
ub00007.jpegの結果
虹絆
人 英日的 2 「
| . 丹
receipt.jpgの結果
モ-リー-ファッタツ~ -( 物販 )
イオンモール大日
MAON POINT 県 」
《 ) 本落 ビジ 3
日 。 2023/01/15 17:23:29
人 お買上
00727-010-00792
時 16643
四づ 四獲得UAON POINT
N POINT 氷水氷氷氷氷氷※氷※氷453
か CO 税込 ) \1.000
合 10P
MR 本"イト 5
内 侯トカのフ 分 DP
8 中イト 2P 8
内23年02月末 10P)
Me イットの有効 寺1 -
売場 。係員 。 1
ーーーーーー
ーー ……あれ…?!処理前一緒じゃん?!
と、今回はたまたまなのか分かりませんが、パラメータは微調整が必要みたいですね。
パラメータの引数の範囲
パラメータの調整を行うことでOCRの精度が上がります。
今回の例では次の2つがそれぞれパラメータの数値の変更が可能です。
- 二値化:
cv2.threshold()関数の第2引数は閾値となり、0〜255の範囲で設定します。この値は画像内のピクセルの強度(灰色度)が閾値より高いか低いかによって、ピクセルを白または黒に設定します。これにより、画像が白黒の二値化された形になります。閾値の選択は画像の特性やテキストの明るさに大きく依存します。明るいテキストには低い値(例えば100)、暗いテキストには高い値(例えば200以上)などが良いみたいです。 - ノイズ除去:
cv2.medianBlur()関数の第2引数はカーネルサイズで、通常は奇数で設定します(1, 3, 5, 7など)。カーネルサイズはフィルタの範囲を決定し、大きい値ほど強いノイズ除去が行われ、しかしテキストの詳細も失われる可能性が高まります。一般的には小さい値(例えば3や5)から始め、ノイズがまだ多い場合には値を上げていくと良いそうです。
パラメータを修正(その1)
次の結果はノイズ除去の部分を変更してみました。
img = cv2.medianBlur(img, 1)としたものです。
実行結果は次の通りです。
00005.jpegの結果
サル 福岡・天神3昌問の攻防
7H
: 全長50<60cmのオス
・ 上立ったけがも表吉した00007.jpegの結果
1 日生
昭和61年 5
子
化
1
が関 2
区直
都千代
住所 | 東京
receipt.jpgの結果
お 日 2023/01/15 17:23・:29g
和 お買上
9 0072/-010-00792
|書号 16643
。今 上獲1 得MAON POINT
NAM UINT 水氷氷氷氷氷氷氷氷氷氷X4D38
"ト※ 旬作(科込 \1.000
高 肌生 - 9E
ル イノ
内 * AM 5P)
0 且和とreceipt.jpg以外は結果が良くなりました。
パラメータを修正(その2)
次の結果はノイズ除去の部分を変更してみました。
# 二値化
_, img = cv2.threshold(img, 50, 200, cv2.THRESH_BINARY)としたものです。
実行結果は次の通りです。
00005.jpegの結果
00007.jpegの結果
2024s(S50630580IE計仙
回 見本
Ei
Em ・receipt.jpgの結果
AD 量0 |
( 、# そる 1 計
IIB 20フ670171
IN居奉
仙人 5う U077/
|番 号
| ME二才記 UN IOIN
WAUN POIN | 番 ち ふる<
に4 計結( )
中 呈
NR 時ポイ
|本 イトアッアガ 分
UM
23年( )7月 本 日放 029
ネ小 ITの有凛期人Et 、。:
T !夫 係員
x香度 ありかのくュし いい」
010
-
1 7/・ノパーウロ
d軸 」
00797
pp4 1
*、タレイ / な4) くバ
いぶがダなぶなが作りうら
\」 000
1 のり「
ロP )
5)
4 、) : 「)
10P/
上 党くただ さい二値化を変えても結果が変わりますね。
両方を変えてみたり、グレースケールは入れないなどパタンは無限大です。
前処理はかなり根気が必要みたいです。
さいごに
今回はOCRの前処理を行なってpytesseractを実行してみました。
パラメータは
それぞれのパラメータは複数の値で試験し、最適な結果を得られる値を選択することをお勧めします。また、異なる種類の画像に対して同じパラメータが必ずしも最適とは限らないため、それぞれのケースでの調整が必要となることも留意してください
この記事がお役に立ったのなら嬉しいです。
最後までお読みいただきありがとうございます。
