

はじめに
OCRにて画像から文字を認識する必要がありました。
以前pyocrを使って画像認識を行ったのですが今回はtesseractを使ったOCRをすることにしました。
今回はtesseractを日本語で認識する方法についてのメモです。
pytesseractについて
pytesseractとは
PyTesseractは、Tesseract OCRエンジンへのPythonラッパーです。Tesseract OCRエンジンは、Googleがオープンソースとして開発している、高精度の光学文字認識(OCR)システムです。
(Googleがオープンソースとして提供したとニュースになったので知っている人は多いかもしれません)
PyTesseractを使用することで、Pythonプログラムから直接Tesseract OCRエンジンを利用し、画像データからテキストデータを抽出することが可能になります。
pytesseractの使い方
pytesseractのインストール方法
pytesseractのインストール方法は次の通りです。
Tesseract OCRのインストール(Ubuntuの例):
Linux(Ubuntu)の場合、コマンドラインから次のコマンドを実行します。
sudo apt install tesseract-ocr次にPython用のTesseractラッパーであるPyTesseractをインストールします。以下のコマンドを実行します。
pip install pytesseractTesseract OCRのインストール(Macの例):
Homebrewを使用してTesseractをインストールします。Terminalを開き、以下のコマンドを実行してください。
brew install tesseract次に、Python用のTesseractラッパーであるPyTesseractをインストールします。以下のコマンドを実行します。
pip install pytesseractTesseract OCRのインストール(Windowの例):
WindowsではまずTesseract-OCRをインストールする必要があります。以下のURLからTesseract-OCRのインストーラをダウンロードし、インストールします。https://github.com/UB-Mannheim/tesseract/wiki
インストール後、Tesseract-OCRへのパスを環境変数に追加します。これにより、コマンドラインからTesseractを呼び出せるようになります。インストールした場所によりますが、通常は以下のようなパスになります。
C:\Program Files\Tesseract-OCR最後に、PythonのTesseractラッパーであるPyTesseractをインストールします。コマンドプロンプトまたはPowershellを開き、以下のコマンドを実行します。
pip install pytesseractソースコードのサンプル
pytesseractのソースコード
pytesseractのソースコードは次のようになります。
画像の前処理などを行なわない一番簡単な方法です。
from PIL import Image
import pytesseract
# 画像の読み込み
image = Image.open('test.png')
# OCRの実行
text = pytesseract.image_to_string(image, lang='jpg')
# 結果の出力
print(text)5行目でOCRを行いたい画像名を指定します。
日本語でOCRを行う場合8行目のlangのパラメータをjpg(日本語)にします。
画像認識と結果
参考画像
次の3つの画像をOCRにかけました。これはpyocrと同じものです。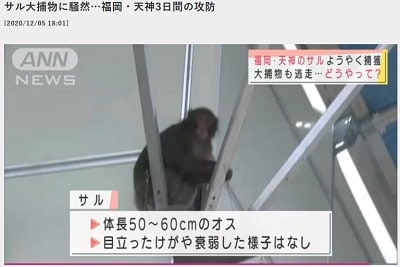
00005.jpeg

00007.jpeg

receipt.jpg
実行結果
実行結果は次の通りです。
00005.jpegの結果
玉
全長50こ60cmのオス00007.jpegの結果
1日生
較
時
ら
トコ
に
LO
す
oz】
中 NE
弁|一
|a
|憶に
ke
Lu
| Pe】
秦| 眉ら
士革
ば
トー】
還半
>
中 寺 |
人W) き思
|receipt.jpgの結果
E-リ=ファンタ> 孤)
イオンモール大日
JO AFOIW 取紅] 、
お 日 Z0Z3/01/15 17:23:29
「 容 お買上
リ 0072/-010-00792
| 見 15543
呈 人
1 叶う回獲得UAON POINT
。 WAON _ POINT番号 *xxxxxxxxxxx4538
PL 込 ) \1, 000
ピ 本本 5P)
直 中 イフ
3 人 中 イトカプ 分 5P)
B 8 日 上有効 432 詳
| *"必トの有効期限にご注意ください思った以上に精度が良くなかったです。おそらく前処理を入れると精度が変わると思います。
(次回前処理の方法についてまとめ記事を作成予定です)
tesseractのTips
tesseractを利用する上でのTipsです。
- 画像の前処理:OCRの精度は、画像の質に大きく依存します。画像にノイズが多い場合や文字が見づらい場合は、OCRの精度が低下します。そのため、OCRを行う前に、適切な前処理を行うことで精度を向上させることが可能です。前処理としては、二値化、ノイズの除去、膨張・縮小処理などがあります。
- 言語設定:Tesseract OCRエンジンは多言語に対応しています。OCRを行う言語を指定することで、その言語の文字に対する認識精度を向上させることができます。言語は
pytesseract.image_to_string関数のlangパラメータで指定します。複数の言語を指定することも可能です。 - ページセグメンテーションモード:Tesseract OCRエンジンは、ページセグメンテーションモード(PSM)という設定を持っています。これは、画像内のテキストの配置をどのように解釈するかを制御するためのもので、13種類のモードがあります。例えば、単一の単語の認識や、縦書きのテキストの認識など、状況に応じて適切なモードを選択することで、認識精度を向上させることが可能です。モードは
pytesseract.image_to_string関数のconfigパラメータで指定します。
さいごに
今回はpytesseractを使った日本語のOCR方法についてでした。
今回は最低限の使い方について書きました。精度は正直微妙でしたが、前処理を入れると精度が上がると思います。
次回は前処理方法について書きたいと思います。
この記事がお役に立ったのなら嬉しいです。
最後までお読みいただきありがとうございます。
